

We weten dat algoritmes op veel terreinen het menselijk beoordelingsvermogen al kunnen overtreffen. Van medische diagnoses tot beeldherkenning, en zelfs het voorspellen van criminaliteit. Maar in werving en selectie heerst er nog steeds veel angst en argwaan rondom algoritmes. Ze zouden kunnen leiden tot bias en vooroordelen, zo wordt vaak gedacht, en daarbij fouten uit het verleden eerder versterken dan tegengaan.
In werving en selectie heerst er nog steeds veel angst en argwaan rondom algoritmes.
 Maar dat ligt er maar net aan hoe je de algoritmes inricht, schrijft MIT-onderzoeker Danielle Li in Fast Company. Het klopt volgens haar dat er algoritmes zijn die kijken welke medewerkers in het verleden succesvol zijn geweest. En als je daarvan de data gebruikt om te voorspellen wie succesvol zullen wórden, zul je inderdaad vooroordelen alleen maar verder bevestigen. Dit was min of meer ook het geval bij de inmiddels veelbesproken en -gewraakte Amazon-casus.
Maar dat ligt er maar net aan hoe je de algoritmes inricht, schrijft MIT-onderzoeker Danielle Li in Fast Company. Het klopt volgens haar dat er algoritmes zijn die kijken welke medewerkers in het verleden succesvol zijn geweest. En als je daarvan de data gebruikt om te voorspellen wie succesvol zullen wórden, zul je inderdaad vooroordelen alleen maar verder bevestigen. Dit was min of meer ook het geval bij de inmiddels veelbesproken en -gewraakte Amazon-casus.
Een andere benadering
Maar er is ook een andere benadering, aldus Li, die er ook al een wetenschappelijk paper over schreef. Die andere benadering gaat ervan uit dat de wereld niet statisch is, en we niet altijd alle data beschikbaar hebben. ‘Vrouwen zijn de laatste jaren bijvoorbeeld massaal de technische arbeidsmarkt opgekomen. Maar zouden bedrijven alleen kijken naar hun historische data om te bepalen wie ze moeten aannemen, dan zouden ze maar weinig voorbeelden tegenkomen van succesvolle vrouwen in dit gebied.’
‘De wereld is niet statisch. Waarom zouden onze algoritmes dat dan wel zijn?’
Tegelijk veranderen functies ook continu: de kwaliteiten die in het verleden succes voorspelden, zijn vandaag de dag misschien niet meer van toepassing. ‘Denk alleen maar aan hoe snel remote work tijdens de pandemie de aard van teamwork, communicatie en onderwijs heeft veranderd.’
Geen statisch probleem
Ze pleit er daarom voor om geen algoritmes te ontwerpen die werving en selectie zien als een statisch probleem. ‘Wat als we algoritmes zouden ontwerpen die het vinden van het beste talent beschouwen als een continu leerproces? En wat als een algoritme actief op zoek gaat naar kandidaten waar het mínder over weet, om zo bewust steeds méér te weten te komen over wat voor kandidaten een goede match zouden kunnen zijn?’
‘Wat als we algoritmes ontwerpen die het beste talent vinden beschouwen als een continu leerproces?
In een recente studie (met collega’s Lindsey Raymond en Peter Bergman) is dát precies wat ze heeft geprobeerd te bereiken. Lang verhaal kort: ze ontwierpen een algoritme dat méér wilde leren over mensen die aanvankelijk niet zouden worden overwogen. Het algoritme gaf een ‘bonus’ aan de onzekerheid over kwaliteit van kandidaten. En dan vooral aan die kandidaten die ondervertegenwoordigd waren in de bestaande data van de organisatie. Denk: minder gangbare studierichtingen, minder bekende universiteiten, andere achtergronden, of demografische ondervertegenwoordiging.
Wie mocht op gesprek?
De focus van het algoritme lag op de uitnodiging voor een eerste sollicitatiegesprek bij 1 van de 500 grootste organisaties in Amerika. Het ging om functies in consultancy, financiële analyse of data science. Kortom: niet alleen goedbetaalde functies dus, maar ook functies die bekend staan om hun gebrek aan diversiteit. De onderzoekers keken naar de eerste cv-screening die deze organisatie hiervoor normaal uitvoert.
Het ging om vacatures in consultancy, financiën en data science, bekend als weinig divers.
In plaats daarvan ontwierpen ze drie andere algoritmes. Het eerste model volgde een typisch statisch model, het zogenoemde SL-model, dat op basis van data uit het verleden voorspelt wie succesvol zal worden. Het tweede model, het ‘updated SL-model‘, leek erg op het eerste model, met als verschil dat het de trainingsdata van het algoritme tijdens de testperiode steeds een update gaf over wie was uitgenodigd voor een interview. En dan was er dus ook nog het derde model, het zogeheten UCB-model, dat het zoeken naar meer informatie beloonde.
Opmerkelijke verschillen
Nadat deze algoritmes op de sollicitanten werden losgelaten, keken de onderzoekers naar wie een uitnodiging kreeg, op basis van elk algoritme. Ook keken ze welke beslissing de menselijke recruiters in het bedrijf namen. Ze deden bewust geen expliciete diversiteitsvoorkeuren in de algoritmes. Toch kwamen er opmerkelijke verschillen uit naar voren. Zo zorgde het UCB-model voor ruim twee keer zoveel uitnodigingen voor Amerikaanse minderheidsgroeperingen (Afro-Amerikaan of Hispanic), van 10 naar 23 procent. Het SL-model en het updated SL-model zorgden daarentegen juist voor een dáling ten opzichte van de keuze van de menselijke recruiters: hier was respectievelijk slechts 2 en 5 procent van de uitnodigingen voor iemand uit een minderheid.
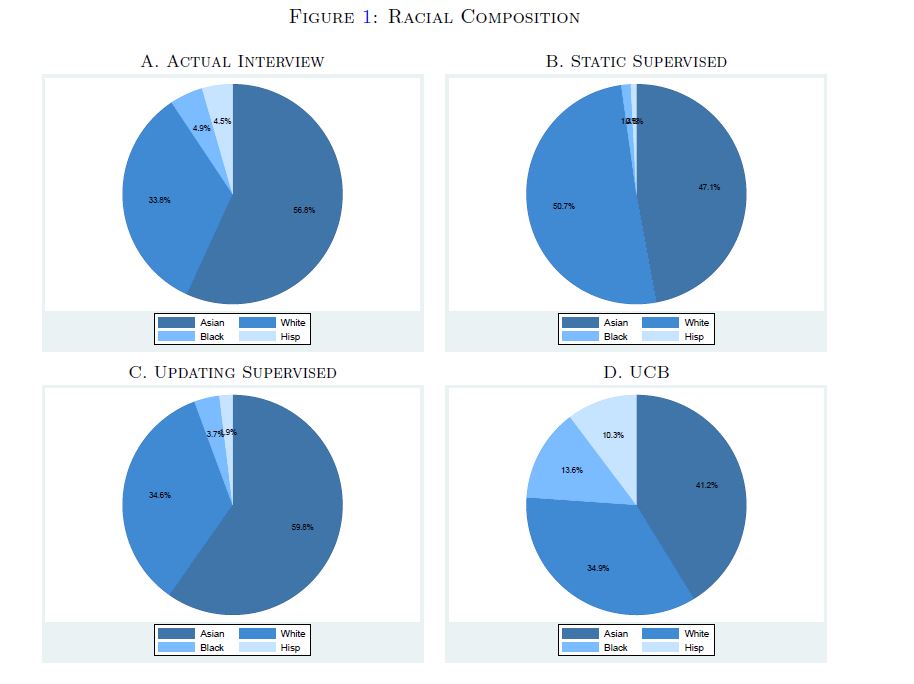
En ook belangrijk: het aandeel van minderheden in het UCB-model bleef permanent hoog, gedurende het hele onderzoek. Dat betekent dat het lerend algoritme deze voorkeur niet afzwakte, maar juist bleef volhouden, in verhouding tot de menselijke keuze en beide SL-modellen. ‘Dit suggereert dat de minderheidskandidaten die het algoritme selecteerde zeker zo goed waren als andere kandidaten – de organisatie had ze simpelweg in het verleden niet zoveel kansen gegeven’, aldus Li.
Ook in gender zat verschil
Ook in gender-resultaten was een verschil te zien. Hier waren de SL-modellen iets sterker in hun voorkeur. De menselijke recruiters kozen in 35 procent van de gevallen voor een vrouw. Bij het UCB-model was dit echter 39 procent, maar bij het gewone SL-model 41 procent en bij het updated SL-model zelfs 50 procent. ‘We denken dat de reden hiervoor is dat de mannelijke sollicitanten gemiddeld meer divers zijn in dimensies als geografie, opleiding, ras, zodat het UCB-algoritme aan hen gemiddeld een hogere ‘bonus’ toekende.’
‘Onze conclusie is helder: als je exploratie in je algoritme inbouwt, werf je meer diverse kandidaten.’
Desalniettemin, concludeert Li: ‘Onze bevindingen zijn volstrekt helder. Als je exploratie in je algoritme inbouwt, dan werf je meer diverse kandidaten. Ook verbeter je de kwaliteit van het talent. En omgekeerd: bedrijven die blijven vasthouden aan statische algoritmes, missen kwalitatieve kandidaten van andere achtergronden dan ze gewend zijn. Dus: wil je de beste kandidaten identificeren? Dan moet je overwegen algoritmes te bouwen die de waarde van meer onderzoek begrijpen.’